research
Brief Descriptions of my current and past projects
CSCI 698 - How to Evaluate Human-AI Collaborative Systems
In this talk, we explore how to rigorously evaluate systems where humans and AI work together. We’ll compare intrinsic and extrinsic evaluations, discuss what each reveals, and highlight why human-centered metrics are essential for understanding real-world effectiveness.
Slides
I am grateful to be advised by Prof. Swabha Swayamdipta and to be collaborating with students in the USC NLP Department and USC Dworak-Peck School of Social Work!
High Level Motivation
My research focuses on human-centered AI alignment, with an emphasis on how AI systems can adapt to domain-specific tasks in high-impact societal applications. I study how domain experts and AI can be effective partners in knowledge extraction and, more broadly, in applications for social good. To this end, I develop new methods and human-grounded evaluations designed to enable outcomes with real societal impact in social services, and healthcare by collaborating closely with community partners and stakeholders.
Past Work and Projects
Uncovering Intervention Opportunities for Suicide Prevention with Language Model Assistants
The National Violent Death Reporting System (NVDRS) documents information about suicides in the United States, including free text narratives (e.g., circumstances surrounding a suicide). In a demanding public health data pipeline, annotators manually extract structured information from death investigation records following extensive guidelines developed painstakingly by experts. In this work, we facilitate data-driven insights from the NVDRS data to support the development of novel suicide interventions by investigating the value of language models (LMs) as efficient assistants to these (a) data annotators and (b) experts. We find that LM predictions match existing data annotations about 85% of the time across 50 NVDRS variables. In the cases where the LM disagrees with existing annotations, expert review reveals that LM assistants can surface annotation discrepancies 38% of the time. Finally, we introduce a human-in-the-loop algorithm to assist experts in efficiently building and refining guidelines for annotating new variables by allowing them to focus only on providing feedback for incorrect LM predictions. We apply our algorithm to a real-world case study for a new variable that characterizes victim interactions with lawyers and demonstrate that it achieves comparable annotation quality with a laborious manual approach. Our findings provide evidence that LMs can serve as effective assistants to public health researchers who handle sensitive data in high-stakes scenarios.
2025
-
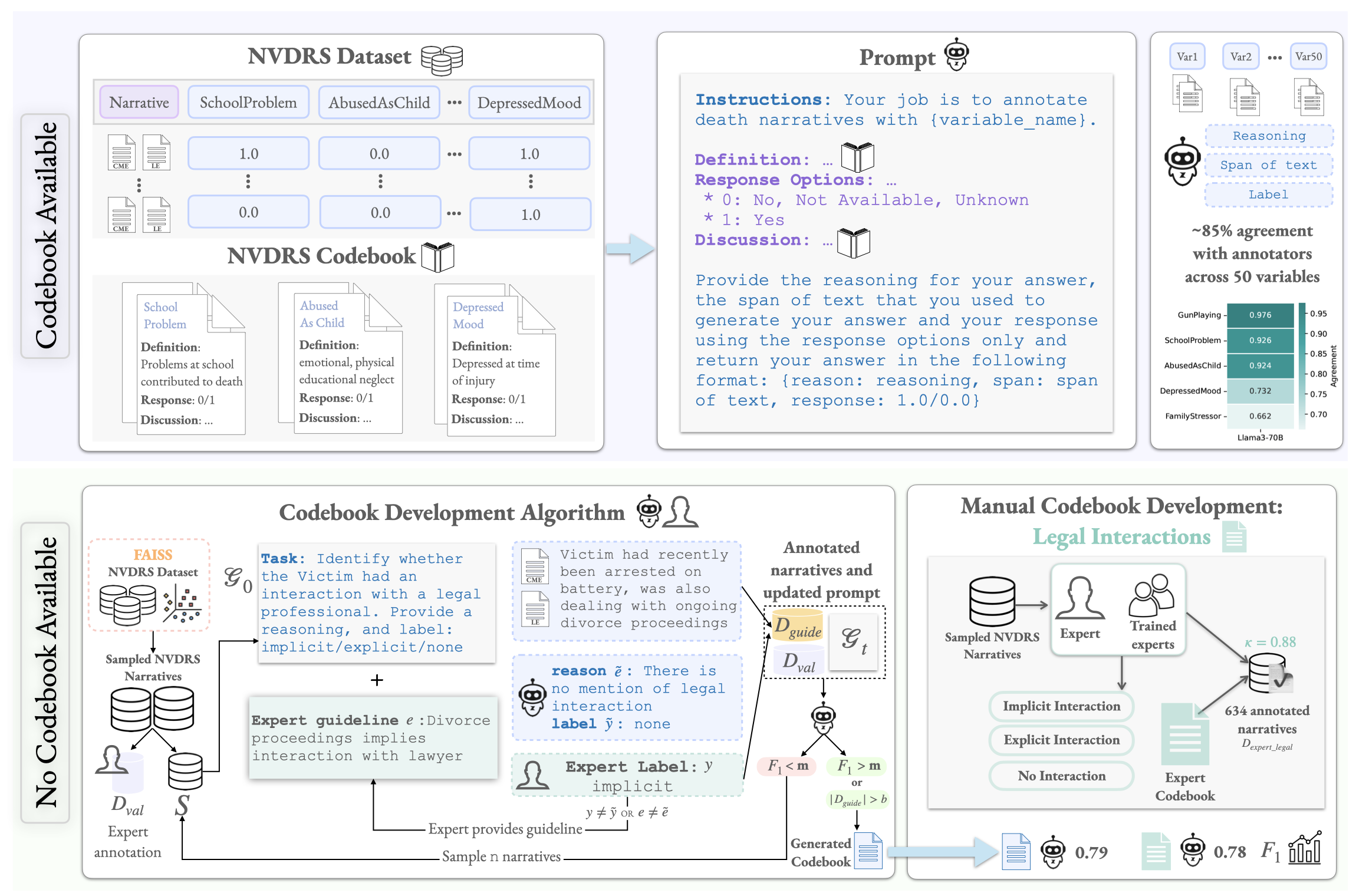 Uncovering Intervention Opportunities for Suicide Prevention with Language Model AssistantsIn EAAMO’25, GenAI4Health NeurIPS’25, 2025
Uncovering Intervention Opportunities for Suicide Prevention with Language Model AssistantsIn EAAMO’25, GenAI4Health NeurIPS’25, 2025

OATH-Frames: Characterizing Online Attitudes Towards Homelessness via LLM Assistants
Public attitudes towards key societal issues, expressed on online media, are of immense value in policy and reform efforts, yet challenging to understand at scale. We study one such social issue: homelessness in the U.S., by leveraging the remarkable capabilities of large language models to assist social work experts in analyzing millions of posts from Twitter. We introduce a framing typology: Online Attitudes Towards Homelessness (OATH) Frames: nine hierarchical frames capturing critiques, responses and perceptions. We release annotations with varying degrees of assistance from language models, with immense benefits in scaling: 6.5x speedup in annotation time while only incurring a 3 point F1 reduction in performance with respect to the domain experts. Our experiments demonstrate the value of modeling OATH-Frames over existing sentiment and toxicity classifiers. Our large-scale analysis with predicted OATH-Frames on 2.4M posts on homelessness reveal key trends in attitudes across states, time periods and vulnerable populations, enabling new insights on the issue. Our work provides a general framework to understand nuanced public attitudes at scale, on issues beyond homelessness.
In this project, we aimed to:
- Evaluate the effectiveness of language models at reasoning about attitudes towards homelessness by developing a codebook grounded in framing theory from sociology (Goffman, 1974)
- Finetune models on an expert annotated dataset to infer our frames developed from our codebook
- Conduct analyses with respect to socio-political dimensions to characterize how attitudes differ across regionality.
2024
-
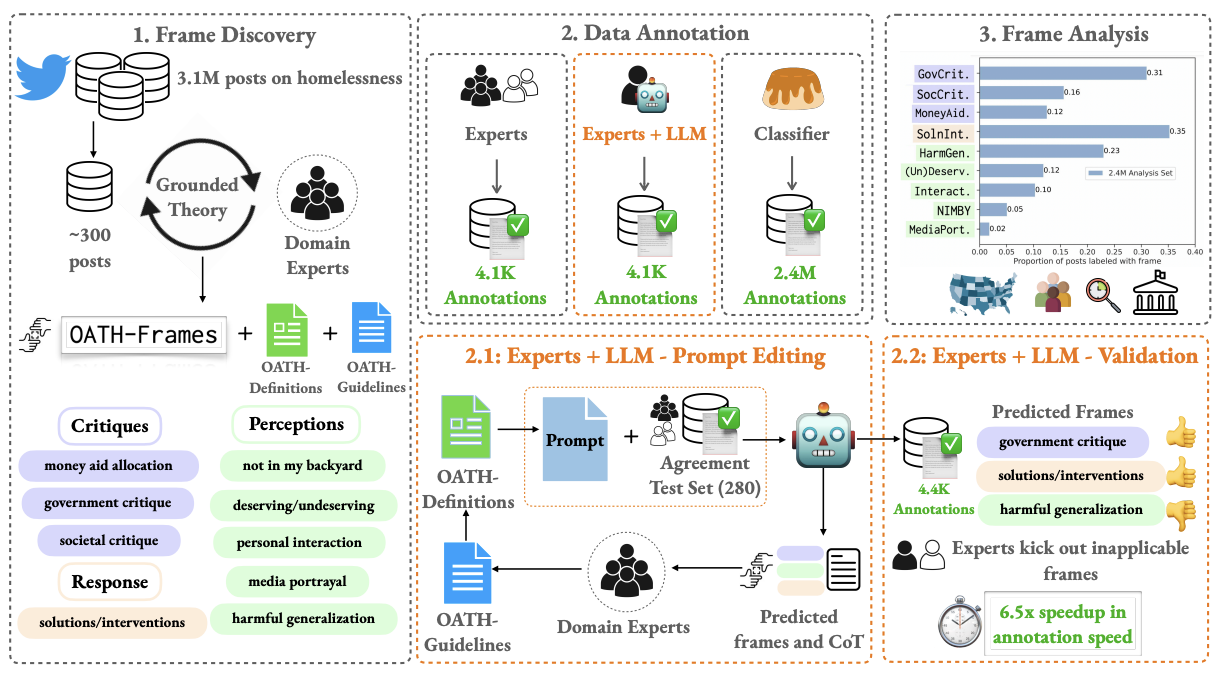 OATH-Frames: Characterizing Online Attitudes Towards Homelessness via LLM AssistantsIn Proceedings of EMNLP, 2024
OATH-Frames: Characterizing Online Attitudes Towards Homelessness via LLM AssistantsIn Proceedings of EMNLP, 2024

Variation of Gender Biases in Visual Recognition Models Before and After Finetuning
In collaboration with Tianlu Wang, Baishakhi Ray, and Vicente Ordonez, we introduce a framework to measure how biases change before and after fine-tuning a large scale visual recognition model for a downstream task.
Many computer vision systems today rely on models typically pretrained on large scale datasets. While bias mitigation techniques have been developed for tuning models for downstream tasks, it is currently unclear what are the effects of biases already encoded in a pretrained model. Our framework incorporates sets of canonical images representing individual and pairs of concepts to highlight changes in biases for an array of off-the-shelf pretrained models across model sizes, dataset sizes, and training objectives.
Through our analyses, we find that:
- Supervised models trained on datasets such as ImageNet-21k are more likely to retain their pretraining biases regardless of the target dataset compared to self-supervised models.
- Models finetuned on larger scale datasets are more likely to introduce new biased associations. Our results also suggest that
- Biases can transfer to finetuned models and the finetuning objective and dataset can impact the extent of transferred biases.
Our work was recently accepted at the Workshop on Algorithmic Fairness through the Lens of Time at NeuRIPS 2023. New Orleans, LA.
2023

Scenario2Vector: scenario description language based embeddings for traffic situations
In collaboration with Aron Harder and Madhur Behl, we propose Scenario2Vector - a Scenario Description Language (SDL) based embedding for traffic situations that allows us to automatically search for similar traffic situations from large AV data-sets. Our SDL embedding distills a traffic situation experienced by an AV into its canonical components - actors, actions, and the traffic scene. We can then use this embedding to evaluate similarity of different traffic situations in vector space.
Safety assessments for automated vehicles need to evolve beyond the existing voluntary self-reporting. There is no comprehensive measuring stick that can compare how far each AV developer is in terms of safety. Our goal in this research is to answer the following question: How can we fairly compare two different AV implementations? In doing so, the aim of this work is to make progress towards an innovative certification method allowing for a fair comparison between AVs by comparing them on similar traffic situations.
The goal of our research is to provide a common metric that will facilitate the comparison of different autonomous vehicle algorithms. In order to compare the different AVs, we need to observe them under similar traffic conditions or scenarios. Our goal therefore is to find similar traffic scenarios from the datasets generated by different AVs. Having found similar traffic situations, we can then observe if the output of one AV is more safe/optimal compared to another. To this end, we also present a first of its kind -Traffic Scenario Similarity (TSS) dataset. This dataset contains 100 traffic video samples (scenarios) and for each sample, it contains 6 candidate scenario videos ranked by human participants based on its similarity to the baseline sample.
Our work was accepted in the Proceedings of the ACM/IEEE 12th International Conference on Cyber-Physical Systems at ICCPS 2021. Nashville, TN.
